After working in the psychiatry department at Michigan, I worked at Aalto University in Espoo, Finland next summer. There, I worked on the Stan math library implementing Gaussian process covariance functions and matrix utilities to make Gaussian process models more feasible in Stan. The ultimate goal was to implement what’s known as “the birthday problem” in Stan. It’s similar to this post: https://likelyllc.com/2022/08/03/additive-gaussian-process-time-series-regression-in-stan/, but with a few caveats. Take a look at BDA3, page 505, section 21.2, for a more rigorous description. Here, we’re summing covariance functions to model different component of a time series. This is difficult since, in order to sample from a multivariate Gaussian distribution, we need to use Cholesky decomposition which scales very poorly, at 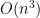

How this is implemented in GPstuff, Aalto University’s MATLAB package for fitting Gaussian process models, is using Laplace Approximation. This is, in layman’s terms, Newton’s method that approximates uncertainty at a posterior mode by using Taylor expansion. This might be fairly trivial using Stan’s autodiff library, paper here: https://arxiv.org/abs/1509.07164.
We initially thought that we’d need implement some optimizer, but I couldn’t get the model to initialize without a crash. The problem was that the autodiff stack was blowing out memory. Without getting too technical, here’s a summary.
Suppose we have to compute the covariance between two points, 
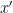

For gradient based algorithms, we need gradients, or derivatives. Suppose, for simplicity, we want to compute the derivative of the above covariance function for parameter 

Next, in the forward pass, we build an expression tree of the above function, which populates the autodiff stack, which is stored on the heap, by starting with a dependent variable, and linking nodes in the expression tree with operators (division, subtraction, addition, etc). On the reverse pass, we evaluate the gradient by starting at the bottom of the tree, using the chain rule. More detail and rigor in section 1.1 of the autodiff paper, “The Stan Math Library: Reverse Mode Autodifferentiation in C++”. If you want to understand autodiff, a good exercise would be to write out the expression tree, for example, with a Weibull distribution, and write out figures 2 and 3.
What ended up happening was that the expression tree was huge, due to the following factors: the complexity (in number of operators) of covariance function, the fact that we are summing covariance matrices (building a larger expression tree), and the fact that we had 
At the end of the summer Professor Dan Simpson and Professor Aki Vehtari got together and worked out how to make this problem possible in Stan. Github issue is here: https://github.com/stan-dev/math/issues/1011. A description of the solution where they pulled it from can be found in GPML, page 114: http://gaussianprocess.org/gpml/chapters/RW.pdf.
But at that time, the summer was about over, my visa was expiring, and I had to leave Finland, the happiest country in the world in 2021, based on the World Happiness Report.
Although the project wasn’t successful, and I didn’t get a publication out of it, I spent a lot of time transferring demos over from GPstuff, implementing GP models of all types, on real and simulated data, and got excellent with modeling with Gaussian processes.
Next, I’ll post the unfinished case study, and may be do a Gaussian process Stan model dump, so people can use the code.

Leave a comment